De algoritmos genéticos y entropía
Hoy presento una idea chorra como cualquier otra, pero que a mi personalmente me emocionó ver que funcionaba, es simplemente un conjunto de un intérprete y un programa que modifica un trozo de bytecode al azar, obviamente pensados para trabajar juntos.
La idea es usarlos para generar un algoritmo usando algo análogo a la evolución natural, aplicando un script (solo por comodidad) para que elija que rama del algoritmo debe ser la que prevalezca, el código con un ejemplo: instructolang.zip (el script usa un trozo de código que se puede encontrar aquí entropy.c, aunque va incluido en el .zip).
Por ahora está muy limitado, solo realiza las operaciones de suma, resta, intercambio de variables y asignación, de todos modos no creo que pueda llegar a ser turing completo por cosas como el problema de parada, que sería necesario resolver para evitar bucles infinitos.
Me olvide de añadir la licencia al código =P , tratadlo como si fuera WTFPL.
La compilación no tiene ninguna dificultad, se entra en la carpeta y se hace "make", sino se puede compilar directamente instructo.c y en la carpeta de ejemplos, entropy.c (este requiere el flag -lm en el compilador).
El ejemplo se apoya en el entropy.c para leer la entropía de un archivo, el objetivo es un algoritmo que obtenga un 8 (lo máximo, creo) de entropía. para crear un archivo para el intérprete se llama al binario, instructo, con los siguientes parámetros
-n -f <archivo a crear> -v <número de variables> -l <número de bucles> -rf
<número de bytes de entrada> -wl <número de bytes de salida>
Para llamarlo desde la carpeta de ejemplos se haría (los datos pueden ser cualquiera, mientras el número de variables sea mayor que en número de bytes de entrada)
1 | |
Se puede obtener información acerca de un archivo creado (y una especie de desensamblado si tiene código dentro) con el flag -i
../instructo -i -f entropy.evo
12 -v 16 -rf 8 -wl 8
Número de bucles: 512
Bytes leídos al principio: 8
Bytes escritos al final: 8
Número de variables: 16
Número de bloques: 1
El bloque número 1 tiene 0 bytes de longitud
Lo de los bloques es una función sin terminar, la idea era que se pueda añadir código bloque a bloque, lo que permite seguir trabajando sobre el mismo archivo sin modificar lo anterior, pero aun no está programada la función para crear nuevos.
Para ejecutar un archivo se hace
../instructo -e -f entropy.evo
Aunque por ahora sólo repetirán lo que pongas (despues de pulsar enter) hasta haber completado los 512 bucles de 8 caracteres.
El flag para modificar los archivos es -c, como siempre -f
Para el ejemplo lo que se hizo fue utilizar un script bash (a continuación más comentado que en el zip)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | |
Lo único que hace es añadir todas las modificaciones que pueda y que al menos no hagan disminuir la entropía mientras esta sea menor que 8. No se acepta solo cuando aumenta la entropía porque esto permitiria cambios mucho menores, sobre todo al principio, donde se está muy limitado. Nota: para el ejemplo el archivo sample son 4096 'A', para evitar que la base añada entropía.
Lanzando el script, se consigue una entropía de 8 en 27 segundos con alrededor de 700 generaciones y 634 bytes de código, aunque esto cambia mucho, al fin y al cabo es aleatorio ;)
La entropía obtenida (en base64), por poner una muestra
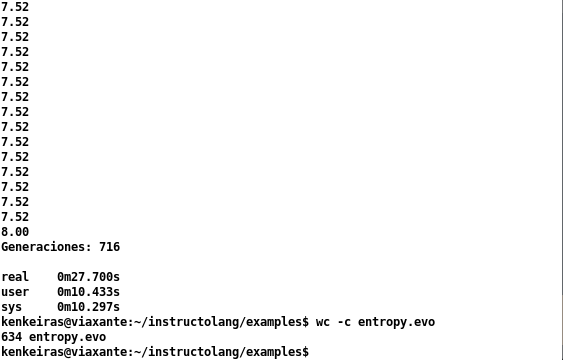
Cabe recordar que 4096 bytes sacados de /dev/urandom tienen más o menos una entropía de 7.95 :D
Por último, el script entropy_minimizer.sh, (abajo más comentado) sirve para reducir el código al mínimo sin hacer que caiga la entropía
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | |
En este caso, puede reducir el código a 58 bytes (42 de código, 14 instrucciones), con lo que el algoritmo quedaría en ( ../instructo -i -f entropy.evo )
SWAP 12 4
SWAP 11 4
ADD 1 4
SWAP 12 1
ADD 3 12
SUB 7 12
SUB 5 4
ADD 1 11
SWAP 10 8
SUB 8 11
SUB 0 5
ADD 2 4
SWAP 10 6
ADD 7 const 175
La notación es similar al ensamblador de Intel (operación destino fuente),
cada número es una variable, a menos que ponga const antes (
La verdad, no creí que un intérprete tan simple, con 3 operaciones pudiera conseguir eso :D, espero ir añadiéndole cosas poco a poco.
Stay tuned [Referencias] http://es.wikipedia.org/wiki/Algoritmo_genético