Un algoritmo de búsqueda de elementos similares
Es curioso, hay momentos en los que uno tiene que buscar una solución a un problema sencillo, por ejemplo, dadas varias listas de elementos, buscar la más parecida a otra nueva, y encontrar una solución (muy simple!). Pero esta solución no aparece en ningún otro sitio, a alguien se le tuvo que ocurrir! será tan simple (y tan inferior a otras), que no merece la pena documentarla?, simplemente uno no es capaz de encontrarla?... es probable :P...
Después de hacer alguna prueba más... resulta que no escala bien, y con grandes datos pierde ventaja rápidamente xD
Bueno, siendo como fuere, ahí va un algoritmo para buscar la lista (o listas), mas cercana a una dada, sin tener que comparar todos los elementos de todas.
La utilidad es bastante directa, en el campo de la IA (Inteligencia Artificial) hay una serie de algoritmos para hacer clasificación, dado un conjunto de entrenamiento etiquetado (con cada elemento asignado a una categoría) encuentra al conjunto al que pertenece un nuevo elemento.
El acercamiento simplista
Uno de estos algoritmos de clasificación es el KNN (K-Nearest Neighbours, los K vecinos más cercanos). El algoritmo es bastante simple, tenemos una lista de elementos con N características, por ejemplo, la longitud y anchura de el śepalo y pétalo de una serie de flores, y asociado el tipo de flor que es, para saber de que tipo es una nueva flor (conociendo estas 4 características), podemos computar su distancia al resto (como la suma de las diferencias de cada característica).
1 2 3 4 5 6 7 8 9 10 | |
Sabiendo las distancias, podemos tomar los K elementos más cercanos y entre ellos escoger la "etiqueta" más común.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
El número que será K se define por ensayo y error, aunque suele ser uno pequeño como 3 podría ser cualquiera.
Para encontrar los valores mas próximos entonces hay que evaluar la distancia desde el punto a clasificar a todos los ejemplos, y ordenarlos según este criterio. El problema, claro, es que el numero de cálculos para cada dato que se quiera clasificar es proporcional al (número de puntos * número de dimensiones, o características)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Podemos probar el algoritmo contra este dataset. Después de descomprimirlo lo primero será cargarlo:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Después tendremos que encontrar una forma de evaluarlo. Una simple y útil es one-out, consiste en lo siguiente: cogemos los datos etiquetados de los que disponemos y por cada uno, lo intentamos clasificar utilizando el resto de la lista. De esta forma sabremos como de bien se hubiera clasificado ese. Cuantos más resultados correctos, mejor, claro.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Con esto ya podemos ir haciendonos una idea de que tal funciona.
1 2 3 4 5 6 7 8 9 10 | |
De 150 elementos sólo 6 fallan (el 4%). Está bastante bien teniendo en cuenta lo simple e intuitivo del algoritmo, verdad? Veamos entonces la forma de hacer esta búsqueda de elementos más rápida (esto fué sobre 150 elementos en 4 dimensiones, es un caso muy limitado).
El algoritmo
Esta idea surgió intentando que la búsqueda sobre ~8000 elementos con más de 20 dimensiones fuese algo más... ligera ante la preocupación de que hubiera problemas cuando el conjunto de datos siguiera creciendo. Está pensado para evitar tener que comprobar todas las dimensiones de todos los elementos, y aún así garantizar que los elementos son los más cercanos, la idea es bastante simple.
Por ejemplo, supongamos que tenemos 3 elementos en 2 dimensiones, y queremos encontrar el más cercano a un punto (0).
Las distancias en cada dimensión a tres puntos (A, B, C) podrían ser:
1 2 | |
Calculamos las distancias en la primera dimensión, y las introducimos en una lista ordenada por la distancia en esa dimensión, junto con el punto al que pertenecen y el número de dimensiones que ha sido computado hasta el momento.
1 | |
Tomamos el primer punto de la lista (el más cercano hasta ahora)
1 | |
Sumamos a la distancia de la primera dimensión la de la segunda (1 + 3) y la introducimos en la lista de acuerdo a la posición que le corresponde por su nueva distancia (sin olvidar cambiar el número de dimensiones computadas).
1 | |
Repetimos el paso con el siguiente elemento más cercano:
1 | |
La nueva distancia será 2 + 1 (la distancia hasta el momento, más el de la siguiente dimensión), así que al añadirlo a la lista se quedará así:
1 | |
(En este momento tanto el punto B como el C podrían ser el primero, da igual, pero si como desempate se hace que el elemento con más número de dimensiónes quede antes nos podemos ahorrar alguna iteración)
Sacamos de nuevo el primer elemento:
1 | |
Y como ya hemos computado todas las dimensiones de este elemento y aún así sigue siendo elmás cercano, no hace falta seguir con el resto de puntos, sabemos seguro que es el más cercano.
Si generalizamos el algoritmo para K vecinos, quedaría algo así:
1. Crear una lista vacía “vecinos”.
2. Calcular la distancia en la primera dimensión de cada elemento hasta el nuevo punto.
3. Organizarlas en una lista de tuplas (distancia, número de dimensiones hasta el momento, punto)
4. Ordenar la lista según la distancia, de forma ascendente
5. Tomar el menor elemento
6. Si se han tomado en cuenta todas las dimensiones para ese punto:
6.1 Pasarlo a la lista de “vecinos” como el siguiente más cercano.
6.2 Si la longitud de la lista de vecinos ya es `K`, ya se ha acabado.
7. Si aún queda alguna dimensión:
7.1 Calcular la nueva distancia sumándole la de la siguiente dimensión a la ya acumulada.
7.2 Introducir en la lista ordenada de acuerdo a la nueva distancia computada, con el nuevo número de dimensiones.
8. Volver al paso `5`
Así de simple, o, en python:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | |
Y eso es todo lo necesario, si repetimos la validación, veremos que el ratio de acierto es el mismo.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Pero si comparamos velocidades, para distintas K, vemos que no se comportan igual.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | |
En resumen, que al principio mantener la lista ordenada es más eficiente,
pero a medida que aumenta la K, se pierde la ventaja y se empieza a
notar el coste de O(log N) por inserción (en vez de uno constante en una
lista normal) que implica mantener la lista ordenada.
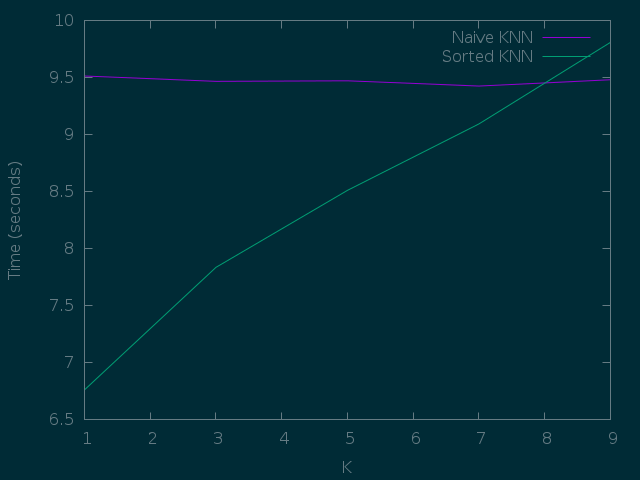
Así que como curiosidad está bien, pero para cosas reales parece que no :P